Background
The fundamental principal behind branch elimination is that expressing
a value as a simple function of its inputs (a single basic block) is
often more efficient than selecting a result through a change in
control flow (branching).Take for example, this simple step function:

|
if ( x < x1 ) |
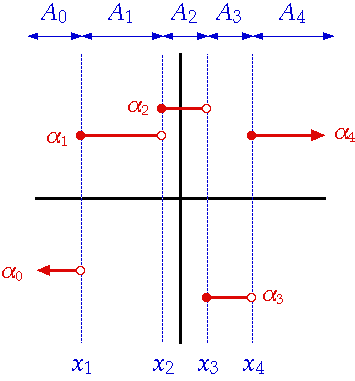
This function can also be expressed by the following branch-free expression, where x is a unsigned 32 bit integer in the range 0 < x < 0x7fffffff
uint32_t x_lt_x1 = (uint32_t)((int32_t)(x - x1) >> 31);
uint32_t x_lt_x2 = (uint32_t)((int32_t)(x - x2) >> 31);
uint32_t x_lt_x3 = (uint32_t)((int32_t)(x - x3) >> 31);
uint32_t x_lt_x4 = (uint32_t)((int32_t)(x - x4) >> 31);
uint32_t result_0 = (x_lt_x4 & a3 ) | (~x_lt_x4 & a4);
uint32_t result_1 = (x_lt_x3 & a2 ) | (~x_lt_x3 & result_0);
uint32_t result_2 = (x_lt_x2 & a1 ) | (~x_lt_x2 & result_1);
uint32_t result = (x_lt_x1 & a0 ) | (~x_lt_x1 & result_2);
Mispredicted branches that continue execution at the wrong address will cause all the instructions that have been executed up to the time the right prediction is found to be canceled, causing a delay in program execution.
Both the PPU and the eight (8) on-board SPUs are in-order, superscalar, RISC platforms designed for one thing - throughput, or executing the maximum number of instructions in the minimum amount of time. In the best case both architectures can issue two (2) instructions per clock cycle. But in order to approach the maximum throughput in performance critical code on either architecture, two things must be true:
- There must be something to execute on each cycle.
- There must be enough instructions between the start of an instruction and the use of its result to cover the latency.
Better Code Scheduling
Regardless of how good the branches are predicted, because branches
negatively impact how code is scheduled, there is often benefit to
reducing them.Most of the work that the compiler's code scheduler will do will be on basic blocks. A basic block is any series of instructions that can be executed unconditionally. Within a block, the compiler will be able to schedule instructions and manage the registers very well. However it's between basic blocks that things get complicated.
Every branch divides the code into three basic blocks.
For example:
A: do some stuff ...
if ( some_condition )
{
B: do some stuff ...
}
C: do some stuff ...
The scheduler must decide:
- Where to put A,B and C (since they do not need to be contiguous).
- How registers will be allocated inside of A, B and C
- Can some_condition be predicited statically?
- etc.
However, by eliminating the branch altogether the compiler's job is made much easier and better code generation will (often) result. There are no guarantees, of course -- in many situations a branch is exactly what you want.
Less branches means easier to schedule loads and stores together. Although GCC has a limited ability to move loads outside of a branch, it's very conservative. For the PPU and SPU, the most effective pattern is (for all objects in a block) LOAD -> UPDATE -> STORE. Use the large register files and pipeline the loads early. For an example of the effective use of this pattern, see the Box Overlap example.
The advantage of consecutive loads is by pushing the loads as far in advance as possible (which is done by loading to the limit of the available registers) the maximum amount of time can be exploited for data to be loaded from the cache.
Easier to profile
Less branches means more predictable performance. Fundamentally, all branch prediction schemes are concerned with average performance. By contrast,
once data and instruction cache hits are accounted for, branch-free code has constant, fixed
performance. This allows programmers who are optimizing a section of
code based on its performance profile with only a small section of
either time or data available, to effectively ignore the
impact varying data may have on performance. This property, in turn,
makes any evaluation of the performance of other systems (e.g. cache
hits) more
accurate and valuable to the programmer.
Easier to test
Less branches means less complexity to test. Approaching full code coverage becomes much easier with every branch
removed. When complex data is mixed with branchy code, there is an explosion of scenarios which must be tested, either
by programmer-devised or automatically-generated tests. Each element of the data must be tested for each branch it may
encounter and every branch must be tested to ensure that it is evaluating the correct data. In branch-free sections of
code, the tests can be limited to concentrate on the data since every element of data will follow
exactly the same path.Additionally, tests are more valuable in branch-free sections of code, since every test must effectively make every possible decision correctly in order to have the correct result. Thus, passing tests on branch-free code are a more accurate and reliable indicator of the validity of the code when compared to testing branchy code, where it can never be gauranteed, simply by looking at the tests, whether or not all the code has even been evaluated once.
Easier to optimize
Easier to organize instruction layer
Expect
better (more predictable) code from the compiler. Beyond the scheduling
impact, the traces are much simpler and most variables will be
write-once (const). Many of the largest failures in optimization are
closer to the front-end where the compiler is re-organizing code.
Simple traces with write-once variables don't need to be re-organized. More predictable gains through inlining
Easier to move to SIMD
Effective use of SIMD instructions depends on keeping the pipeline full
as long as possible. This generally requires branch elimination.
Branch-free scalar code is significantly easier to move to Altivec on
the PPU, or the SPU instruction set than branchy code.
Improved accuracy of remaining dynamic branch predictions
Dynamic
branch prediction it has its limits, like everything else. Branch
prediction is based on taking certain bits of the branch address and
looking them up in a branch history table. The table has values that
range from very-unlikely to very-likely and the which set of
instructions that are fetched are a function of that value. Then,
depending on the actual result, the value in the table is adjusted for
the next time. Branch history tables are very small though and in all
likelyhood there are many branches that will end up using the same
entry in the table making it more and more inaccurate.
Harder to understand (?)
Predicated
results, or branch-free code, may impact readability somewhat.
Programmers are acustomed to reading and writing branchy code. However,
much of this can made clearer through well named variables and
predicate functions/macros.
