Programming with Branches, Patterns and Tips
Mike Acton
April 11, 2006
April 11, 2006
Better Performance Through Branch Elimination
Part 1: IntroductionPart 2: Background on Branching
Part 3: Benefits to Branch Elimination
Part 4: Programming with Branches, Patterns and Tips
Part 5: More Techniques for Eliminating Branches
Additional Examples:
Increment And Decrement Wrapping Values
Occasionally you have a set of values that you want to wrap around as you increment and decrement them. But the straightfoward implementation can have a big impact on processors where comparisons and branches are expensive (e.g. PowerPC). This article presents a straightforward branch-free implementation of these functions.
Choosing to Avoid Branches: A Small Altivec Example
An example of why less instructions doesn't always equal faster code.
Branch-free implementation of half-precision (16 bit) floating point
The goal of this project is serve as an example of developing some relatively complex operations completely without branches - a software implementation of half-precision floating point numbers.
Branch Patterns, Using GCC
GCC follows some straightforward rules that are useful to know when programming with branches:Rule #1: Forward branches are not likely to be taken
Rule #2: Backward branches are likely to be taken
Rule #3: Switch Statements
Here also are some programming tips for improving the performance of branches for those cases when they either cannot be avoided or are a benefit to performance:
Tip #1: Don´t change GCC´s default static prediction
Tip #2: Boolean Operators Affect Static Branch Prediction
Tip #3: Simple traces (not shorter traces) will almost always generate better code in GCC
Tip #4: Bitwise operators generate fewer branches and microcoded instructions than logical operators
Rule #1: Forward branches are not likely to be taken
Forward branches are generated for if statements. The rationale for making them not likely to be taken is that the processor can take advantage of the fact that instructions following the branch instruction may already be placed in the instruction buffer inside the Instruction Unit. Instructions in the target path of the branch will have to be fetched from the L1 cache, L2 cache or main storage before being executed, causing delays in the program execution. It follows that ifs whose conditions are more likely to be false will perform better.
When writing an if-else statement, always make the "then" block more likely to be executed than the else block, so the processor can take advantage of instructions already placed in the instruction fetch buffer.
if ( *list == NULL )
{
/*
Code to initialize the list. This
occurs only the first time an element
is inserted.
*/
}
else
{
/*
Code to insert an element in the list.
This will be executed for all inserts
except the first.
*/
}
Might be instead:
if ( *list != NULL )
{
/*
Code to insert an element in the list.
This will be executed for all inserts
except the first.
*/
}
else
{
/*
Code to initialize the list. This
occurs only the first time an element
is inserted.
*/
}
Also, rewrite your ifs that prematurely terminate the function via a return when they are unlikely to occur, which should be the rule for error conditions. Invert the condition, place the code that follows the if inside the "then" block and put the return inside the “else” block.
ptr = malloc(sizeof(some_structure));
if (ptr == NULL)
{
return -1;
}
/*
Malloc successful, continue execution.
*/
Might be instead:
ptr = malloc(sizeof(some_structure));
if (ptr != NULL)
{
/*
Malloc successful, continue execution.
*/
}
else
{
return -1;
}
Rule #2: Backward branches are likely to be taken
Backward branches are generated for while, do-while and for statements. The reason to make them likely is that loops are generally executed one or more times, so the branch at the end of the loop that tests for the condition is likely to be taken.
int
while_test( int a, int b, int c )
{
int count;
while ( c < a )
{
c += b;
a--;
count++;
}
return (count);
}
while_test:
stwu 1,-16(1) # allocate stack
b .L9 # jump to condition test
.L11:
add 5,5,4 # c += b
addi 3,3,-1 # a--
addi 9,9,1 # count++
.L9:
cmpw 7,5,3 # check c < a
blt+ 7,.L11 # iterate if true
mr 3,9 # = count
addi 1,1,16 # restore stack
blr # return
int
do_while_test( int a, int b, int c )
{
int count;
do
{
c += b;
a--;
count++;
}
while ( c < a );
return (count);
}
do_while_test:
stwu 1,-16(1) # allocate stack
.L13:
add 5,5,4 # c += b
addi 3,3,-1 # a--
cmpw 7,5,3 # check c < a
addi 9,9,1 # count++
blt+ 7,.L13 # iterate if true
mr 3,9 # = count
addi 1,1,16 # restore stack
blr # return
int
for_test( int a, int b, int c )
{
int count;
for(;c<a;count++)
{
c += b;
a--;
}
return (count);
}
for_test:
stwu 1,-16(1) # allocate stack
b .L27 # jump to condition test
.L28:
add 5,5,4 # c += b
addi 3,3,-1 # a--
addi 9,9,1 # count++
.L27:
cmpw 7,5,3 # check c < a
blt+ 7,.L28 # iterate if true
mr 3,9 # = count
addi 1,1,16 # restore stack
blr # return
It's important to note that the compiler rearranges the while and for loops to make the test at the end. It's a good optimization that will save a branch instruction, because otherwise loops that test at the beginning would have a conditional branch at the start to check for the loop condition and an unconditional branch at the end to reiterate the loop.This however adds a constraint to the compiler that prevents it from further optimizing the code. In order to put the test at the end of the loop and save one branch instruction, the compiler generates an unconditional branch before the start of the loop that will be executed only once and jumps to the condition test at the end. This branch prevents the optimization of the test itself. The cmpw instruction in the previous for and while examples put its result in CR7, and the branch instruction that just follows tests for CR7. This will cause a stall in the execution pipeline, because the branch will have to wait for the result of cmpw to be written in CR7.
The do-while loop doesn't suffer from this problem. Without the branch to the test condition, the compiler can reschedule instructions in order to fill the space where the stall would occur with some computation. The do-while example above clearly shows that the compiler moved the add 9,9,1 (count++) instruction in between cmpw and the branch. While the addition is being computed, the result of the comparison is being saved into CR7 to be used in the branch that follows. Changing for and while loops to test at the end will increase the performance of the program.
int
strlen(const char *str)
{
int len = 0;
while (*str++ != ‘\0’)
len++;
return len;
}
int
strlen(const char *str)
{
int len = -1;
do
{
len++;
} while (*str++ != ‘\0’);
return len;
}
Try to change for and while loops to do-while loops. This generally makes the test for the loop condition faster.
There is a catch in the conversion of the for loop, however. The semantics of the continue statement in the case of the for mandates that a continue issued in the body of the for cause the update part of the for declaration to be executed.
When converting for loops that have continue statements is their bodies, change those statements to an explicit goto to the update part of the code near the end of the do-while loop.
In cases where it's mandatory to test for the loop condition at the beginning, convert the loop into a do-while and add an if to test if it has to be executed the at least once. While this adds additional instructions to account for the if, the do-while will provide a better instruction schedule and will execute faster.
void
print_list(const list_t *list)
{
while (list != NULL)
{
printf(“%d\n”, list->value);
list = list->next;
}
}
void
print_list(const list_t *list)
{
if (list != NULL)
{
do
{
printf(“%d”\n”, list->value);
list = list->next;
} while (list != NULL);
}
}
Change for and while loops where it's absolutely necessary to test for the condition at the beginning to an if to test the condition and a do-while to iterate the loop. This allows for more explicit control of branch prediction and blocking.
Rule #3: Switch Statements
For PPU and SPU, GCC generates either a search through the case values by a series of conditional branches, or a single indirect jump through a table of addresses indexed by the case value. The compiler determines which method to use through the following logic: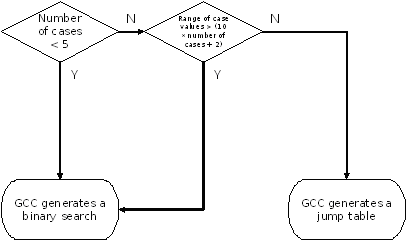
i.e.,
if ( case_count < 5 )
{
branch_search();
}
else if ( range_of_values > ( ( 10 * case_count ) + 2 ) )
{
branch_search();
}
else
{
jump_table();
}
For binary searches, each case value will generate two branch instructions. The first branches to the case code if the case value is the right one, and the second divides the remaining case values into two sets, the values greater than and less than the one that was just tested. The “leaves” of this hard coded binary search are jumps to the default label or out of the switch statement.
Binary search (number of cases < 5)
void test_0( int a )
{
switch ( a )
{
case 0:
call_0();
break;
case 1:
call_1();
break;
case 2:
call_2();
break;
case 3:
call_3();
break;
}
}
test_0:
ceqi $2,$3,1 # check a == 1
hbra .L10,.L1 # hint that branch at L10
# will branch to L1
stqd $lr,16($sp) # save return address
stqd $sp,-32($sp) # save stack pointer
ai $sp,$sp,-32 # allocate stack
brnz $2,.L4 # if a == 1 go to L4
cgti $4,$3,1 # check a > 1
brz $4,.L9 # if a < 1 go to L9
ceqi $5,$3,2 # check a == 2
brnz $5,.L5 # if a != 2 go to L5
ceqi $6,$3,3 # check a == 3
.L10:
brz $6,.L1 # if a != 3 go to L1
brsl $lr,call_3 # execute call_3()
br .L1 # go to L1
.L9:
nop $127
brnz $3,.L1 # if a != 0 go to L1
brsl $lr,call_0 # execute call_0()
br .L1 # go to L1
.L4:
brsl $lr,call_1 # execute call_1()
br .L1 # go to L1
.L5:
nop $127
brsl $lr,call_2 # execute call_2()
.L1:
ai $sp,$sp,32 # restore stack
lqd $lr,16($sp) # load return address
nop $127
bi $lr # return
Binary search (range of case values > 10 x number of cases + 2)
void test_2( int a )
{
switch ( a )
{
case 1:
call_0();
break;
case 2:
call_1();
break;
case 3:
call_2();
break;
case 4:
call_3();
break;
case 52:
call_4();
break;
}
}
test_2:
ceqi $2,$3,3 # check a == 3
hbra .L30,.L20 # hint that branch at L30
# will branch to L20
stqd $lr,16($sp) # save return address
stqd $sp,-32($sp) # save stack pointer
ai $sp,$sp,-32 # allocate stack
brnz $2,.L24 # if a == 3 go to L24
cgti $4,$3,3 # check a > 3
brz $4,.L28 # if a <= 3 go to L28
ceqi $7,$3,4 # check a == 4
brnz $7,.L25 # if a == 4 go to L25
ceqi $8,$3,52 # check a ==52
.L30:
brz $8,.L20 # if a != 52 go to L20
nop $127
br .L29 # go to L29
.L28:
ceqi $5,$3,1 # check a == 1
brnz $5,.L22 # if a == 1 go to L22
ceqi $6,$3,2 # check a == 2
brz $6,.L20 # if a != 2 go to L20
brsl $lr,call_1 # execute call_1()
br .L20 # go to L20
.L24:
brsl $lr,call_2 # execute call_2()
br .L20 # go to L20
.L25:
brsl $lr,call_3 # execute call_3()
br .L20 # go to L20
.L22:
brsl $lr,call_0 # execute call_0()
br .L20 # goto L20
.L29:
nop $127
brsl $lr,call_4 # execute call_4()
.L20:
ai $sp,$sp,32 # restore stack
lqd $lr,16($sp) # load return address
nop $127
bi $lr # return
Binary searches in a balanced search binary tree – which is the case for the code GCC generates – guarantee log2n comparisons in the worst case, where n is the number of nodes, or case values, to find a specific value or make sure the value is not in the tree. Although pretty nice (it can locate one amongst 4,294,967,296 values with just 32 comparisons), consider if the case value that is most likely to be chosen is exactly the one that takes the most comparisons to be found, or if the default case is the most likely to be chosen. In those cases, the program will perform poorly.
For jump tables, the code is much more straightforward. GCC generates code that checks if the expression value is within the case value ranges, branching to the default case or out of the switch if not, and then uses the value to look up the target address in an array (the jump table).
Jump Tables
void test_1( int a )
{
switch ( a )
{
case 0:
call_0();
break;
case 1:
call_1();
break;
case 2:
call_2();
break;
case 3:
call_3();
break;
case 4:
call_4();
break;
case 5:
call_5();
break;
}
}
test_1:
shli $6,$3,2 # tmp1 = a times 4
stqd $lr,16($sp) # save return address
ila $4,.L19 # tmp2 = address of L19
stqd $sp,-32($sp) # save stack pointer
clgti $3,$3,5 # check (unsigned)a > 5
ai $sp,$sp,-32 # allocate stack
a $5,$6,$4 # tmp3 = tmp1 + tmp2
lqx $2,$6,$4 # tmp4 = load four
# addresses
rotqby $2,$2,$5 # rotate branch address
# to preferred slot of
# tmp4
brnz $3,.L11 # if a > 5 go to L11
nop $127 # no operation
bi $2 # branch to tmp4
.align 2
.align 2
.L19: # address table
.word .L13
.word .L14
.word .L15
.word .L16
.word .L17
.word .L18
.L17:
brsl $lr,call_4 # execute call_4()
br .L11 # go to L11
.L13:
brsl $lr,call_0 # execute call_0()
br .L11 # go to L11
.L14:
brsl $lr,call_1 # execute call_1()
br .L11 # go to L11
.L15:
brsl $lr,call_2 # execute call_2()
br .L11 # go to L11
.L16:
brsl $lr,call_3 # execute call_3()
br .L11 # go to L11
.L18:
nop $127
brsl $lr,call_5 # execute call_5()
.L11:
ai $sp,$sp,32 # restore stack
lqd $lr,16($sp) # load return address
nop $127
bi $lr # return
Although jump tables use just two branches, it’s better to rethink the problem and try to get away with code that doesn’t use branches at all. Moreover, deletions or additions to the case values can make GCC switch from a binary search to a jump table or vice-versa, resulting in performance impacts that are hard to track.
Avoid switches for high performance code. Changes in case values can result in non-obvious performance impacts.
When the switch is small – number of case values less than five in the case of both the PPU and SPU – the number of comparisons GCC generates is comparable to a series of if statements. However, GCC cannot take into account the likelihood of each case being taken. In this case, manually converting the switch to a series of ifs, ordering the comparisons from most likely to least likely, can have a big impact in performance. If the default case is the most likely to occur, test for it before all other case values.
Eliminate small switches. Convert to a series of if statements contained by an outer branch (when the default case is likely). Alternatively convert to a branch-free expression.
Sometimes medium size switches that would perform better with jump tables are generated to use a binary search by GCC. In those cases, converting the switch statement to a series of labels and using an array of addresses (using GCC’s &&label_name syntax) which can be indexed by the switch expression and used along with goto can make the program run faster.It’s important to note that GCC does not have a definition for medium-size switches, only for small, large-sparse and large-dense. The definition of medium-size switches is subjective to how critical the code is and memory constraints of the program. Almost always a jump table will perform better than a binary search, but if the case values are sparse the size of the array of addresses can grow pretty fast. The conversion to jump tables is only useful when the switch is located in performance critical code and where enough memory is available to hold the resulting array of addresses.
Convert medium-size switches to jump tables (using GCC's &&label_name syntax).
Large, sparse arrays will be coded with a binary search, and because of the size of the resulting array of addresses, it’s not feasible to manually code them with a jump table. In those cases, using a hash function on both the switch expression and case values can make the switch become dense.The C code below:
switch ( x )
{
case 0x0001:
...
...
...
...
break;
case 0x010B:
...
...
...
...
break;
case 0x2507:
...
...
...
...
break;
case 0xFCDF:
...
...
...
...
break;
case 0x9AD5:
...
...
...
...
break;
case 0x60A0:
...
...
...
...
break;
}
...would become:
switch ( x & 0xF )
{
case 0x1:
if ( x == 0x0001)
{
...
}
break;
case 0xB:
if ( x == 0x010B)
{
...
}
break;
case 0x7:
if ( x == 0x2507)
{
...
}
break;
case 0xF:
if ( x == 0xFCDF)
{
...
}
break;
case 0x5:
if ( x == 0x9AD5)
{
...
}
break;
case 0x0:
if ( x == 0x60A0)
{
...
}
break;
}
In the example above, if x is guaranteed to be one of the case values, it’s possible to remove the if statements and save one branch per case.If the resulting switch is small or medium-sized, further optimization is possible with the use of the techniques described above.
Convert large, sparse switches to smaller ones by pre-processing the case values (i.e. via a hash function), then manually convert to a jump table depending on the number of cases and their likelihood.
Tip #1: Don´t change GCC´s default static prediction
The default static prediction generated by GCC can be overridden using the __builtin_expect compiler extension. It takes a condition as the first argument and the expected truth value of the condition as the second argument. For example, the list example would become:
if ( *list == NULL )
{
/*
Code to initialize the list. This
occurs only the first time an element
is inserted.
*/
}
else
{
/*
Code to insert an element in the list.
This will be executed for all inserts
except the first.
*/
}
Would become:
if ( __builtin_expect((*list == NULL), 0) )
{
/*
Code to initialize the list. This
occurs only the first time an element
is inserted.
*/
}
else
{
/*
Code to insert an element in the list.
This will be executed for all inserts
except the first.
*/
}
So the expression is likely to be false and GCC generates a forward branch to the else block which is likely to be taken. As this will perform worse than the case where the fall-through path is the likely continuation address, it is preferable to not change the default GCC prediction and change the conditional and loop statements to benefit from the prediction.
int32_t
test( int32_t a, int32_t b, int32_t c )
{
if ( a == 0 )
{
return (b + c);
}
return (a + c);
}
Would be (on the PPU):
cmpdi 0,3,0
add 4,4,5
add 0,3,5
extsw 3,4
beqlr- 0
extsw 3,0
blr
And,
int32_t
test( int32_t a, int32_t b, int32_t c )
{
if (__builtin_expect( (a == 0 ), 1 ))
{
return (b + c);
}
return (a + c);
}
Would be (on the PPU):
cmpdi 0,3,0
add 4,4,5
add 0,3,5
extsw 3,4
beqlr+ 0
extsw 3,0
blr
Don’t use the __builtin_expect extension to change GCC’s default branch prediction, rearrange your code instead.
Only use this extension to convert what would have been dynamically predicted branches to statically predicted ones,
and only where the data has been analyzed and the predicability is well-known in advance.
Tip #2: Boolean Operators Affect Static Branch Prediction
Static prediction rules become increasingly complicated with a mix of boolean operators are used (due to C short-circuiting rules), and often the results will be unexpected.
Avoid complex boolean expressions.
To match C short-circuiting rules, in complex comparisons "and" implies "unlikely"If the cases are actually equally likely (or worse, in the wrong order), loads will be "hidden" behind badly predicted branches which will generate TWO penalties
- The mispredicted branch, and
- Loads late in the pipeline (which will likely stall)
int
box_test_overlap_and( const Box* restrict const a, const Box* restrict const b )
{
return fabs(a->center.e[0] - b->center.e[0]) <= a->extent.e[0] + b->extent.e[0] &&
fabs(a->center.e[1] - b->center.e[1]) <= a->extent.e[1] + b->extent.e[1] &&
fabs(a->center.e[2] - b->center.e[2]) <= a->extent.e[2] + b->extent.e[2];
}
box_test_overlap_and: stwu 1,-16(1) lfs 3,0(3) li 0,0 lfs 11,0(4) fsubs 1,3,11 lfs 2,12(3) lfs 0,12(4) fadds 12,2,0 fabs 13,1 fcmpu 7,13,12 cror 30,28,30 beq- 7,.L7 .L2: mr 3,0 addi 1,1,16 blr .L7: lfs 9,4(3) lfs 10,4(4) fsubs 6,9,10 lfs 7,16(3) lfs 8,16(4) fadds 4,7,8 fabs 5,6 fcmpu 0,5,4 cror 2,0,2 bne+ 0,.L2 lfs 0,8(3) lfs 11,8(4) fsubs 1,0,11 lfs 2,20(3) lfs 3,20(4) fadds 13,2,3 fabs 12,1 fcmpu 1,12,13 cror 6,4,6 bne+ 1,.L2 li 0,1 b .L2Note that each sub-expression is completely evaluated before the branch. i.e. There is no pipelining among the sub-expressions.
When cases are not equally likely, use "and" and order by most->least likely.
To match C short-circuiting rules, in complex comparisons "or" implies "likely"
int
box_test_overlap_nor( const Box* restrict const a, const Box* restrict const b )
{
return !(fabs(a->center.e[0] - b->center.e[0]) > a->extent.e[0] + b->extent.e[0] ||
fabs(a->center.e[1] - b->center.e[1]) > a->extent.e[1] + b->extent.e[1] ||
fabs(a->center.e[2] - b->center.e[2]) > a->extent.e[2] + b->extent.e[2]);
}
box_test_overlap_nor: stwu 1,-16(1) lfs 3,0(3) li 0,0 lfs 11,0(4) fsubs 1,3,11 lfs 2,12(3) lfs 0,12(4) fadds 12,2,0 fabs 13,1 fcmpu 7,13,12 bgt- 7,.L9 lfs 9,4(3) lfs 10,4(4) fsubs 6,9,10 lfs 7,16(3) lfs 8,16(4) fadds 4,7,8 fabs 5,6 fcmpu 0,5,4 bgt- 0,.L9 lfs 0,8(3) lfs 11,8(4) fsubs 1,0,11 lfs 2,20(3) lfs 3,20(4) fadds 13,2,3 fabs 12,1 fcmpu 1,12,13 bgt- 1,.L9 li 0,1 .L9: mr 3,0 addi 1,1,16 blrNote that each sub-expression is still completely evaluated before the branch. However the number of targets has been reduced from two to one since the compiler assumes that the most likely scenario is evaluating the instruction stream completely in order.
When cases are equally likely, use "or". The order is not important.
Tip #3: Simple traces (not shorter traces) will almost always generate better code in GCC
Something about what a trace is.Something about simplifying expressions and combining at the end.
int
box_test_overlap_combine_1( const Box* restrict const a, const Box* restrict const b )
{
float acx = a->center.e[0];
float acy = a->center.e[1];
float acz = a->center.e[2];
float aex = a->extent.e[0];
float aey = a->extent.e[1];
float aez = a->extent.e[2];
float bcx = b->center.e[0];
float bcy = b->center.e[1];
float bcz = b->center.e[2];
float bex = b->extent.e[0];
float bey = b->extent.e[1];
float bez = b->extent.e[2];
float adiff_cx = fabs( acx-bcx );
float adiff_cy = fabs( acy-bcy );
float adiff_cz = fabs( acz-bcz );
float sum_ex = aex + bex;
float sum_ey = aey + bey;
float sum_ez = aez + bez;
int overlap_x = adiff_cx <= sum_ex;
int overlap_y = adiff_cy <= sum_ey;
int overlap_z = adiff_cz <= sum_ez;
int overlap = overlap_x && overlap_y && overlap_z;
return (overlap);
}
box_test_overlap_combine_1: stwu 1,-16(1) lfs 9,0(3) li 10,0 lfs 8,4(3) lfs 11,0(4) lfs 10,4(4) fsubs 6,9,11 fsubs 5,8,10 lfs 12,12(3) lfs 1,12(4) lfs 3,8(3) lfs 4,8(4) fadds 9,12,1 fsubs 1,3,4 lfs 13,16(4) lfs 7,16(3) fadds 8,7,13 fabs 11,6 fabs 10,5 lfs 2,20(3) lfs 0,20(4) fadds 13,2,0 fabs 12,1 fcmpu 1,11,9 fcmpu 6,10,8 cror 6,4,6 cror 26,24,26 mfcr 11 rlwinm 11,11,7,1 fcmpu 7,12,13 mfcr 9 rlwinm 9,9,27,1 cror 30,28,30 and. 0,11,9 mfcr 0 rlwinm 0,0,31,1 cmpwi 7,0,0 beq- 0,.L11 beq- 7,.L11 li 10,1 .L11: mr 3,10 addi 1,1,16 blrThe compiler has been able to reduce the number of branches from three to two by using Condition Register (CR) boolean instructions. Additionally, the entire expression is evaluated in a single basic block which can be better pipelined and both branches occur at the end.
Although the PPU has a sophisticated set of instructions for dealing with predicates and the CR, the amount of effort taken by the compiler to schedule these instructions is minimal. The CR is also a very limited resource, shared by all the execution units.
The FPU is especially inhibited by CR - it effectively only has one CR slot to use. (CR is divided into 8x4bit chunks). Integer compares can directly index a CR slot. Also many CR modifying instructions are microcoded, which inhibits the ability to make maximum use of the predicate instructions.
Also note the “and.” instruction is used in order to move the result of the logical and into the CR. The “and.” instruction is microcoded on the PPU and will cause a performance penalty. See: Avoiding Microcoded Instructions On The PPU.
Use the LOAD->COMPARE->COMBINE pattern.
Tip #4: Bitwise operators generate fewer branches and microcoded instructions than logical operators.
Bitwise operation on boolean results "encourages" use of CR boolean instructions, many of which are microcoded. Using bitwise operators to generate the result produces better results.
int
box_test_overlap_combine_2( const Box* restrict const a, const Box* restrict const b )
{
float acx = a->center.e[0];
float acy = a->center.e[1];
float acz = a->center.e[2];
float aex = a->extent.e[0];
float aey = a->extent.e[1];
float aez = a->extent.e[2];
float bcx = b->center.e[0];
float bcy = b->center.e[1];
float bcz = b->center.e[2];
float bex = b->extent.e[0];
float bey = b->extent.e[1];
float bez = b->extent.e[2];
float adiff_cx = fabs( acx-bcx );
float adiff_cy = fabs( acy-bcy );
float adiff_cz = fabs( acz-bcz );
float sum_ex = aex + bex;
float sum_ey = aey + bey;
float sum_ez = aez + bez;
int overlap_x = adiff_cx <= sum_ex;
int overlap_y = adiff_cy <= sum_ey;
int overlap_z = adiff_cz <= sum_ez;
int overlap = overlap_x & overlap_y & overlap_z;
return (overlap);
}
box_test_overlap_combine_2: stwu 1,-16(1) lfs 9,0(3) addi 1,1,16 lfs 8,4(3) lfs 1,0(4) lfs 11,4(4) fsubs 4,9,1 fsubs 3,8,11 lfs 10,8(3) lfs 12,8(4) fsubs 1,10,12 lfs 0,12(4) lfs 7,12(3) lfs 5,16(3) lfs 6,16(4) fadds 11,7,0 fadds 12,5,6 fabs 9,4 fabs 8,3 lfs 2,20(3) lfs 13,20(4) fadds 0,2,13 fabs 10,1 fcmpu 6,9,11 fcmpu 1,8,12 cror 26,24,26 cror 6,4,6 mfcr 4 rlwinm 4,4,27,1 fcmpu 7,10,0 mfcr 0 rlwinm 0,0,7,1 cror 30,28,30 and 3,4,0 mfcr 9 rlwinm 9,9,31,1 and 3,3,9 blr
In addition to being free of microcoded instructions, this version is also branch-free. Because the overlap_x & overlap_y & overlap_z expression does not use boolean operators, there is no branch implied and it has been reduced to a function of the result of the floating point comparison operations, for which there are PowerPC instructions.
Combine boolean results with bitwise operators.
About the authors
Mike Acton is a Senior Architect working on PS3/Cell research at Highmoon Studios (Vivendi-Universal Games). Most recently, Mike was the Lead Special Effects Programmer for Darkwatch at Highmoon Studios (previously Sammy Studios) in Carlsbad, CA. Previously Mike has held Lead Programming, Playstation 2 Engine Development and Research roles with Yuke's, VBlank and BlueSky/Titus. He worked for Sony Interactive Studios in PSX development. Mike has made regular appearances as a speaker at SCEA develpment conferences and has spoken at GDC. Mike Acton is not a framework-happy C++ programmer. He actually likes C. And assembly. In his spare time he develops hardware on FPGAs in VHDL.
André de Leiradella started with computers in 1981 with a ZX-81 compatible with a built-in BASIC interpreter. Two years later he was already using assembly to code faster programs in this platform. Today André is a Support Analyst working at Xerox, and uses he's spare time to code pet projects that goes from using script languages to control a VNC server and fixed point expression compilers for J2ME, to a full Java bytecode interpreter.
André has a Computer Science degree and a M.Sc. degree in Artificial Intelligence and has a fairly good knowledge of many areas of Computer Science, managing to dig deep on any specific subject when needed.
May Also Interest You
Understanding Strict Aliasing (Mike Acton)Strict aliasing has been part of C programming for the better part of the last decade but a thorough understanding of the details of this feature is still clouded in mystery for many programmers. Examine detailed examples and some perculiarities of GCC's implementation.
Demystifying The Restrict Keyword (Mike Acton)
Optimizing data access is a critical part of good performance. Read on to find out how to use the restrict keyword to open up a whole class of optimizations that were previously impossible for a C compiler.
Avoiding Microcoded Instructions On The PPU (Mike Acton)
Executing instructions from microcode can wreck havok on inner loop performance. Find out which instructions are microcoded and how to avoid them.
FullMoon [geocites.com] (André de Leiradella)
This plugin is an attempt to make object plugin coding for Moray [stmuc.com] easier, by allowing authors to code them using a script language called Lua. Lua is a procedural language with some OOP, meaning it's very easy to learn because it's similar to C and Pascal and it allows a very powerful design of the object interface.
APF Project [geocities.com] (André de Leiradella)
This library is targetted at programs that need to find paths in small mazes. Diagonal movements are allowed.